
目录
背景
第一部分
第二部分 总结
参考文献及资料
背景
在自然语言处理中,词语通常是表达语义的最小单位,所以从文本中提取词语是最基础的数据预处理步骤,这就是分词。
英文文本书写词与词之间通常用空格间隔,而中文文本就需要进行分词了。分词的方法按照方法有:基于词典的分词方法、基于统计的分词方法。
基于词典的分词方法
该方法实现是构建一个词典,然后按照策略对文本进行扫描,文本中子串命中词典中的词,则分词成功。
其中扫描策略有:正向最大匹配、逆向最大匹配、双向最大匹配、最少词数分词
基于统计的分词方法
基于统计的分词方法是从大量已经分词的文本中,利用统计学习方法来学习词的切分规律,从而实现对未知文本的切分。随着大规模语料库的建立,基于统计的分词方法不断受到研究和发展,渐渐成为了主流。
统计学习方法有:隐马尔可夫模型(HMM)、条件随机场(CRF)和基于深度学习的方法。
汉语分词方法:
- 基于字典、词库匹配的分词方法(基于规则)
基于字符串匹配分词,机械分词算法。将待分的字符串与一个充分大的机器词典中的词条进行匹配。分为正向匹配和逆向匹配;最大长度匹配和最小长度匹配;单纯分词和分词与标注过程相结合的一体化方法。所以常用的有:正向最大匹配,逆向最大匹配,最少切分法。实际应用中,将机械分词作为初分手段,利用语言信息提高切分准确率。优先识别具有明显特征的词,以这些词为断点,将原字符串分为较小字符串再机械匹配,以减少匹配错误率,或将分词与词类标注结合。 - 基于词频度统计的分词方法(基于统计)
相邻的字同时出现的次数越多,越有可能构成一个词语,对语料中的字组频度进行统计,基于词的频度统计的分词方法是一种全切分方法。jieba是基于统 计的分词方法,jieba分词采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合,对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。 - 基于知识理解的分词方法。
该方法主要基于句法、语法分析,并结合语义分析,通过对上下文内容所提供信息的分析对词进行定界,它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断。这类方法试图让机器具有人类的理解能力,需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式。因此目前基于知识的分词系统还处在试验阶段。
Jieba库是优秀的中文分词第三方库,中文文本需要通过分词获得单个的词语。
- 支持四种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- paddle模式,利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。paddle模式使用需安装paddlepaddle-tiny,
pip install paddlepaddle-tiny==1.6.1。目前paddle模式支持jieba v0.40及以上版本。jieba v0.40以下版本,请升级jieba,pip install jieba --upgrade。PaddlePaddle官网
安装:
1 | pip3 install paddlepaddle |
本文的代码环境:
1 | Python 3.8.8 |
第一部分 案例
先看一个案例(参考官版):
1 | # encoding=utf-8 |
输出回显:
1 | Paddle Mode: 我/来到/北京清华大学 |
第二部分 分词原理和源码解析
关于jieba分词的原理,官方github上的算法说明是:
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的
HMM模型,使用了Viterbi算法
下面逐一介绍,语句案例使用下面的文本:
1 | 在复旦大学数学系读研究生 |
2.1 构造前缀词典
2.1.1 离线词典
jieba项目提供了3个词典文件:dict.txt.big和dict.txt.small以及默认词典dict.txt,其中词汇量分别是:584429、109750、349046。三个词典的数据格式相同,每一行有三列,第一列是词,第二列是词频,第三列是词性。例如下面的节选(dict.txt):
1 | ... |
例如,第一行:复旦 240 nz,其中复旦是词,240是词频,nz表示:其他专有名词。那么这些词典是如何生成的?
根据项目作者(fxsjy)说明,来源主要有两个,PKU(人民日报语料库)切分语料和MSR(微软亚洲研究院语料库)的切分语料。另一个是作者收集的一些txt小说,用ictclas进行切分(可能有一定误差)。 然后用python脚本统计词频。
然后PKU是1998年时产物,随着语言的发展,其分词早已经不大符合大众习惯。
2.1.2 前缀词典
在介绍前缀词典前,需要说明一下概念:前缀词。例如词典中复旦大学,前缀词集合有:”复”、”复旦”、”复旦大”。统计词典中所有的词形成的前缀词典如下所示(构造前缀词典需要用到离线词典前两列):
1 | ... |
其中“复旦大”作为“复旦大学”的前缀,它的词频却为0,主要是便于后面有向无环图的构建。归纳一下这个过程:
初始化一个前缀词典数据对象;
遍历离线词典中每一行数据(例如:
复旦大学 393 nt);遍历该词条(例如:
复旦大学)的前缀,如果前缀(”复”、”复旦”、”复旦大”)对应的键不在字典里,就把该前缀设为字典新的键,对应的键值设为0(例如:”复旦大”),如果前缀在字典里,则什么都不做;将本次所有词典前缀词更新进入前缀词典;
重复离线词典中所有词条,最后就完成了前缀词典的构造。
另外在构造前缀词典时,会对统计词典里所有词条的词频做一下累加,累加值等计算最大概率路径时会用到。
2.2 生成有向无环图(DAG)
然后基于前面构建的前缀词典,对目标文本进行切分,案例文本还是:在复旦大学数学系读研究生。具体过程描述如下:
注:在jieba分词中,对每个汉字都是通过在文本中的位置来标记的。使用位置为键名(key),相应划分的末尾位置构成的列表为value的mapping数据结构。可以结合下面的案例理解:
1 | 对于“在”,没有前缀,只有一种切分方式。 |
接下来我们

这个DAG图,最后使用字典数据结构表示:
1 | {0: [0],1: [1,2,4],2: [2],3: [3,4],4: [4],5: [5,6,7],6: [6],7: [7],8: [8],9: [9,10,11],10: [10],11: [11]} |
用正则表达式分割句子后,对每一个单独的子句会生成一个有向无环图。
具体方式为:先定义一个空的python字典,然后遍历子句,当前子句元素的索引会作为字典的一个键,对应的键值为一个python列表(初始为空),然后会以当前索引作为子串的起始索引,不断向后遍历生成不同的子串,如果子串在前缀词典里且键值不为0的话,则把子串的终止索引添加到列表中。
这样等遍历完子句的所有字后,对应的DAG就生成好了。(子串的键值如果是0,则说明它不是一个词条)
2.3 计算最大概率路径
DAG的起点到终点会有很多路径,需要找到一条概率最大的路径,然后据此进行分词。可以采用动态规划来求解最大概率路径。
具体来说就是:从子句的最后一个字开始,倒序遍历子句的每个字,取当前字对应索引在DAG字典中的键值(一个python列表),然后遍历该列表,当前字会和列表中每个字两两组合成一个词条,然后基于词频计算出当前字到句尾的概率,以python元组的方式保存最大概率,元祖第一个元素是最大概率的对数,第二个元素为最大概率对应词条的终止索引。
词频可看作DAG中边的权重,之所以取概率的对数是为了防止数值下溢。有了最大概率路径,分词结果也就随之确定。
2.4 未登录词分词
当出现没有在前缀词典里收录的词时,会采用HMM模型进行分词。HMM模型有5个基本组成:观测序列、状态序列、状态初始概率、状态转移概率和状态发射概率。分词属于HMM的预测问题,即已知观测序列、状态初始概率、状态转移概率和状态发射概率的条件下,求状态序列。结巴分词已经内置了训练好的状态初始概率、状态转移概率和状态发射概率。
句子会作为观测序列,当有新句子进来时,具体做法为:先通过Viterbi算法求出概率最大的状态序列,然后基于状态序列输出分词结果(每个字的状态为B、M、E、S之一)。
至此,结巴分词的原理就简单介绍完了。
最后举一个简单的例子:
假如待分词的句子为: “这几天都在学自然语言处理”。
首先依据前缀词典生成DAG:
{ 0: [0],
1: [1, 2],
2: [2, 3],
3: [3],
4: [4],
5: [5],
6: [6, 7, 9],
7: [7],
8: [8, 9],
9: [9],
10: [10, 11],
11: [11] }
句子元素对应的索引会作为字典的键,对应键值的第一项与当前索引相同,其余项会与当前索引组成词条,这个词条在前缀词典里且对应键值不为0。
生成的DAG如下:
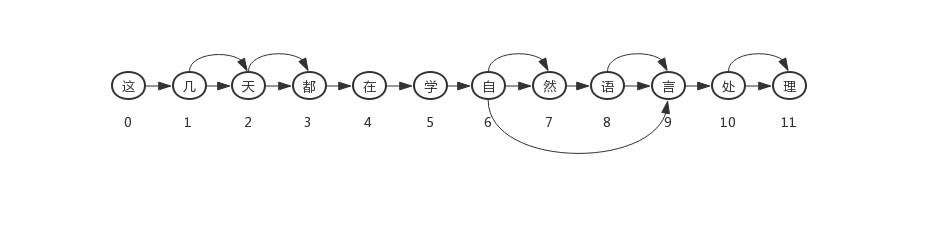
然后采用动态规划求出的最大概率路径为:
{12: (0, 0),
11: (-9.073726763747516, 11),
10: (-8.620554852761583, 11),
9: (-17.35315508178225, 9),
8: (-17.590039287472578, 9),
7: (-27.280113467960604, 7),
6: (-22.70346658402771, 9),
5: (-30.846092652642497, 5),
4: (-35.25970621827743, 4),
3: (-40.95138241952608, 3),
2: (-48.372244833381465, 2),
1: (-50.4870755319817, 2),
0: (-55.92332690525722, 0)}
最大概率路径按句子索引倒序排列,但分词时会从索引0开始顺序遍历句子。
具体做法为:
首先遍历0,0对应的键值最后一项为0,即词的长度为1,遇到长度为1的词时(即单字)先不分,继续往后看,然后遍历1,1对应的键值最后一项为2,即词的长度为2,这时会把索引为0的单字作为词分割出来,然后接着把索引1、2对应的词分割出来,然后遍历3,3对应的键值最后一项为3,属于单字,先不分,索引4、5同理,然后遍历6,6对应的键值最后一项为9,即词的长度为4,注意,这里索引3、4、5对应的单字序列(即“都在学”)如果不在前缀词典中或者在前缀词典中但键值为0,则会对单字序列采用HMM模型进行分词,否则的话,会对单字序列每个字进行分词,分好之后把索引6、7、8、9对应的词分割出去,然后遍历10,10对应的键值最后一项为11,即词的长度为2,直接把索引10、11对应的词分割出去,至此分词结束。
总结一下:
在遇到长度>=2的词之前会把它前面出现的所有单字保存下来。
如果保存下来的单字序列长度为0,则直接把当前词分割出去;
如果保存下来的单字序列长度为1,则直接把单字作为词分割出去,然后把后面词分割出去;
如果保存下来的单字序列长度>1,会分两种情况:假如单字序列不在前缀词典中或者在前缀词典中但键值为0,则会对单字序列采用HMM模型进行分词,否则的话,会对单字序列每个字进行分词。
最后分好的词为:[‘这’, ‘几天’, ‘都’, ‘在’, ‘学’, ‘自然语言’, ‘处理’]。
第三部分 jieba源码解析
3.1 算法流程
jieba.init.py中实现了jieba分词接口函数cut(self, sentence, cut_all=False, HMM=True)。
jieba分词接口主入口函数,会首先将输入文本解码为Unicode编码,然后根据入参,选择不同的切分方式。本文主要以精确模式进行讲解,因此cut_all和HMM这两个入参均为默认值。
切分方式选择:
re_han = re_han_default
re_skip = re_skip_default
块切分方式选择,
cut_block = self.cut_DAG
函数cut_DAG(self, sentence)首先构建前缀词典,其次构建有向无环图,然后计算最大概率路径,最后基于最大概率路径进行分词,如果遇到未登录词,则调用HMM模型进行切分。本文主要涉及前三个部分,基于HMM的分词方法则在下一文章中详细说明。
3.2 前缀词典构建
get_DAG(self, sentence)函数会首先检查系统是否初始化,如果没有初始化,则进行初始化。在初始化的过程中,会构建前缀词典。
构建前缀词典的入口函数是gen_pfdict(self, f),解析离线统计词典文本文件,每一行分别对应着词、词频、词性,将词和词频提取出来,以词为key,以词频为value,加入到前缀词典中。对于每个词,再分别获取它的前缀词,如果前缀词已经存在于前缀词典中,则不处理;如果该前缀词不在前缀词典中,则将其词频置为0,便于后续构建有向无环图。
jieba分词中gen_pfdict函数实现如下,
f是离线统计的词典文件句柄
1 | def gen_pfdict(self, f): |
为什么jieba没有使用trie树作为前缀词典存储的数据结构?
对于get_DAG()函数来说,用Trie数据结构,特别是在Python环境,内存使用量过大。经实验,可构造一个前缀集合解决问题。
该集合储存词语及其前缀,如set([‘数’, ‘数据’, ‘数据结’, ‘数据结构’])。在句子中按字正向查找词语,在前缀列表中就继续查找,直到不在前缀列表中或超出句子范围。大约比原词库增加40%词条。
该版本通过各项测试,与原版本分词结果相同。
测试:一本5.7M的小说,用默认字典,64位Ubuntu,Python 2.7.6。
Trie:第一次加载2.8秒,缓存加载1.1秒;内存277.4MB,平均速率724kB/s;
前缀字典:第一次加载2.1秒,缓存加载0.4秒;内存99.0MB,平均速率781kB/s;
此方法解决纯Python中Trie空间效率低下的问题。
同时改善了一些代码的细节,遵循PEP8的格式,优化了几个逻辑判断。
3.2 有向无环图构建
有向无环图,directed acyclic graphs,简称DAG,是一种图的数据结构,顾名思义,就是没有环的有向图。
DAG在分词中的应用很广,无论是最大概率路径,还是其它做法,DAG都广泛存在于分词中。因为DAG本身也是有向图,所以用邻接矩阵来表示是可行的,但是jieba采用了Python的dict结构,可以更方便的表示DAG。最终的DAG是以{k : [k , j , ..] , m : [m , p , q] , …}的字典结构存储,其中k和m为词在文本sentence中的位置,k对应的列表存放的是文本中以k开始且词sentence[k: j + 1]在前缀词典中的以k开始j结尾的词的列表,即列表存放的是sentence中以k开始的可能的词语的结束位置,这样通过查找前缀词典就可以得到词。
get_DAG(self, sentence)函数进行对系统初始化完毕后,会构建有向无环图。
从前往后依次遍历文本的每个位置,对于位置k,首先形成一个片段,这个片段只包含位置k的字,然后就判断该片段是否在前缀词典中。
如果这个片段在前缀词典中,
1.1 如果词频大于0,就将这个位置i追加到以k为key的一个列表中;
1.2 如果词频等于0,如同第2章中提到的“北京大”,则表明前缀词典存在这个前缀,但是统计词典并没有这个词,继续循环;
如果这个片段不在前缀词典中,则表明这个片段已经超出统计词典中该词的范围,则终止循环;
然后该位置加1,然后就形成一个新的片段,该片段在文本的索引为[k:i+1],继续判断这个片段是否在前缀词典中。
jieba分词中get_DAG函数实现如下,
有向无环图构建主函数
1 | def get_DAG(self, sentence): |
以“去北京大学玩”为例,最终形成的有向无环图为,
{0: [0], 1: [1,2,4], 2: [2], 3: [3,4], 4: [4], 5: [5]}
3.3 最大概率路径计算
3.2章节中构建出的有向无环图DAG的每个节点,都是带权的,对于在前缀词典里面的词语,其权重就是它的词频;我们想要求得route = (w1,w2,w3,…,wn),使得 ∑weight(wi) 最大。
如果需要使用动态规划求解,需要满足两个条件,
重复子问题
最优子结构
我们来分析一下最大概率路径问题,是否满足动态规划的两个条件。
重复子问题
对于节点wi和其可能存在的多个后继节点Wj和Wk,
任意通过Wi到达Wj的路径的权重 = 该路径通过Wi的路径权重 + Wj的权重,也即{Ri -> j} = {Ri + weight(j)}
任意通过Wi到达Wk的路径的权重 = 该路径通过Wi的路径权重 + Wk的权重,也即{Ri -> k} = {Ri + weight(k)}
即对于拥有公共前驱节点Wi的节点Wj和Wk,需要重复计算达到Wi的路径的概率。
最优子结构
对于整个句子的最优路径Rmax和一个末端节点Wx,对于其可能存在的多个前驱Wi,Wj,Wk…,设到达Wi,Wj,Wk的最大路径分别是Rmaxi,Rmaxj,Rmaxk,有,
Rmax = max(Rmaxi,Rmaxj,Rmaxk,…) + weight(Wx)
于是,问题转化为,求解Rmaxi,Rmaxj,Rmaxk,…等,
组成了最优子结构,子结构里面的最优解是全局的最优解的一部分。
状态转移方程为,
Rmax = max{(Rmaxi,Rmaxj,Rmaxk,…) + weight(Wx)}
jieba分词中计算最大概率路径的主函数是calc(self, sentence, DAG, route),函数根据已经构建好的有向无环图计算最大概率路径。
函数是一个自底向上的动态规划问题,它从sentence的最后一个字(N-1)开始倒序遍历sentence的每个字(idx)的方式,计算子句sentence[idx ~ N-1]的概率对数得分。然后将概率对数得分最高的情况以(概率对数,词语最后一个位置)这样的元组保存在route中。
函数中,logtotal为构建前缀词频时所有的词频之和的对数值,这里的计算都是使用概率对数值,可以有效防止下溢问题。
jieba分词中calc函数实现如下,
1 | def calc(self, sentence, DAG, route): |
第四部分 高阶使用
4.1 自定义词典
每一行为三个部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。该词典文件需为utf8编码。
自定义词典加载缓慢问题:
将自定义词典设置成jieba词库的内置词典,找到jieba库下面的dict.txt,将自定义词典加入到dict字典中。具体步骤如下: 1.找到默认的结巴词库,将默认词库模型加载到本机缓存,之后每次都从本地缓存中去加载默认词库,缓存文件为 jieba.cache。 2.将自己的自定义词典加入dict.txt中,第一列:词;第二列:词频;第三列:词性。如果不知怎么设置词频、词性,可以将其设置成3和n。 3.保存之后,找到之前缓存文件jieba.cache并删除,路径C:\Users\20655\AppData\Local\Temp\jieba.cache。重新生成缓存文件,注意:每次需要更新内置词典,都需要重新生成缓存文件jieba.cache
通过对比之后,将自定义词典设置成默认的jieba词典,比从外部导入词典会效率会大大的提高。
https://www.jianshu.com/p/e23fe5d06ea2
4.2 关键词抽取
4.3 延迟加载机制
4.4 停用词
停用词表:https://github.com/goto456/stopwords
复制代码
1 | import jieba |
https://github.com/fxsjy/jieba
https://bbs.huaweicloud.com/blogs/252899
https://blog.csdn.net/u013982921/article/details/81122928
参考文献及资料
1、1998人民日报标注语料库(PFR),链接:https://www.heywhale.com/mw/dataset/5ce7983cd10470002b334de3
2、对Python中文分词模块结巴分词算法过程的理解和分析,链接:https://blog.csdn.net/rav009/article/details/12196623