
历史背景
最近几年Deep Learning、AI人工智能、机器学习等名词称为新闻热点,特别是Google Deep mind的Alpha Go战胜韩国棋手李世石,让深度学习妇孺皆知。
首先从概念范畴上讲,deep learning属于机器学习的一个分支,追根溯源其实是人工神经网络。顾名思义,人工神经网络是借鉴人类神经网路的结构原型,算生物仿生学(虽然人类到现在也没弄明白大脑原理)。

例如下面就是一个3层结构的人工神经网络(1个输入层、1个隐藏层、1个输出层)。
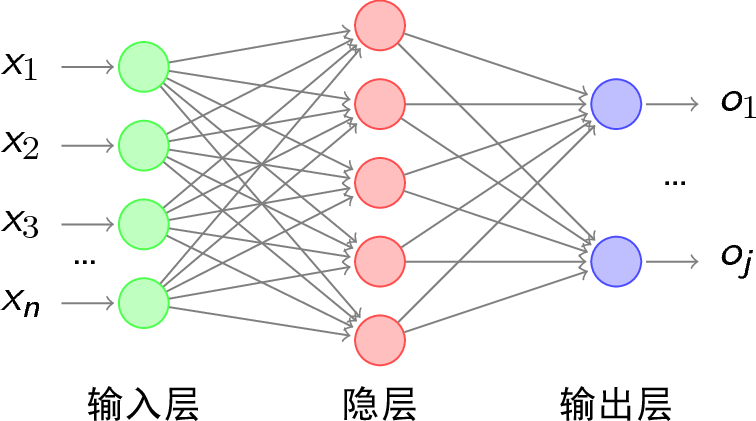
1989年Yann LeCun使用反向传播算法(Back Propagation)应用于多层神经网络训练。但一旦层数较大,网络的参数和训练计算量成倍增加,通常需要几周时间才能完成参数训练,另外反向传播算法容易梯度爆炸。研究人员获得好的结果,时间成本太大。
所以当时机器学习研究方向中,支持向量机(SVM)算法比多层神经网络更为热门,神经网络研究则相当冷门。
直到2012 年的ImageNet 图像分类竞赛中,Alex Krizhevsky使用CNN(卷积)多层网络(共8层、6千万个参数)赢得当年的比赛,领先第二名10.8个百分点。并且模型使用GPU芯片训练、引入正则技术(Dropout)。
从此多层神经网络成为机器学习中的研究热点。而为了“洗白”以前暗淡历史,被赋予了新的名称:Deep Learning。
深度学习背后的数学
目前的人工智能均属于弱人工智能(不具备心智和意识)。事实上,深度学习目前主要在图像识别和声音识别场景中获得较好的效果。深度学习的成为热点,依赖于两方面条件的成熟:
- 算力的提升,训练中大量使用GPU。
- 大量数据的获得和沉淀。
弱人工智能背后的理论基础依赖于数学和统计理论,其实更应该算数据科学的范畴。
比如输入数据具有$m$维特征,而输出特征为$k$维(例如如果是个二分类问题,$k=2$)。我们使用3层神经网络(输入层为$m$维,即含有$m$个神经元;隐藏层为$n$维,输出层为$k$维)用来训练。
通常我们将输入数据看成$R^m$($m$维欧几里得空间),输出数据看成$R^k$($k$维欧式空间),如下图:

从数学上看,神经网络的结构定义了一个函数空间:${R^{n}} \xrightarrow{\text{f}} {R^{h}} \xrightarrow{\text{g}} {R^{m}}$ 。这个函数空间中元素是非线性的(隐藏层和输出层有非线性的激活函数)。空间中每个函数由网络中的参数(w,b)唯一决定。
神经网络训练的过程可以形象的理解为寻找最佳函数的过程:输入层“吃进”大量训练数据,通过非线性函数的作用,观察输出层输出结果和实际值的差异。这是一个监督学习的过程。
- 如果差异(误差)在容忍范围内,停止训练,认为该函数是目标函数。
- 如果差异较大,反向传播算法根据梯度下降的反向更新网络中的参数(w,b),即挑选新的函数。
- 重新喂进数据,计算新挑选函数的误差。如此循环,直到找到目标函数(也可设置提前结束训练)。
为什么神经网络的发展最后偏向的是“深度”呢?即增加层数来提高网络的认知能力。为什么没有“宽度学习”?即增加网络隐藏层的维度(宽度)。
其实从数学上可以证明深度网络和“宽度网络”的等价性。证明提示:考虑网络定义的函数空间出发。
写在最后(畅想未来)
深度学习的局限性思考
目前深度学习被各行各业应用于各种场景,而且有些特定场景取得了良好结果。但是传统的深度学习仍属于监督学习,更像一个被动的执行者,按照人类既定的规则,吃进海量数据,然后训练。
那么深度网络是否真的理解和学到了模式?还是只学会对有限数据的模式识别?甚至就是一个庞大的记忆网络?这都是值得我们深度思考的。
GAN对抗网络
那么怎么能说明模型真的学习并理解了。我们提出了一个原则:如果你理解了一个事物,那么你就可以创造它。这样就发明了GAN对抗网络。让网络自己去创造事物,然后用现实数据去监督,当网络的创造能力和现实接近时,我们认为网络学会了。
其实思想类似传统的遗传算法。
强化学习
另外传统的深度学习,输入的环境(数据)是固定的。然而现实中我们学习过程其实是:环境(数据)与学习个体互相作用的交互过程。这个学习过程人类由于时间有限,是个漫长的过程。但是计算机有个天然优势,可以同时启用成千上万的学习个体完成与环境数据的交互学习过程。例如Alpha Go启用上万个体,两两互搏,配上强大算力,短时间完成学习,这是人类不可企及的。
迁移学习
人类学习中还有个方法叫:触类旁通。其实就是不同场景训练模型的借鉴。例如A场景得到训练好的模型(网络参数),对于新的场景B,可以尝试直接用A场景的网络(或部分使用,拼接),以此来减少训练成本。
那么新的问题来了:是否具有统一的迁移标准,即什么模型是适合迁移的?如果这些问题没有理论基础支持,迁移学习也摆脱不了“炼丹术”的非议。
深度学习从过去的暗淡无色到现在的光耀夺目。
然而任何方法都是有边际效应的。
人工智能的终点还很遥远,谁是下一颗耀眼的明星,需要学界和工业界共同探索。
2018年4月15日 夜