
目录
- 术语说明
- 背景
- 第一部分 Apache Spark运行模式介绍
- 第二部分 Spark on Yarn
- 第三部分 Pyspark Application原理
- 第四部分 Python on Yarn配置及运行
- 第五部分 总结
- 参考文献及资料
背景
Apache Spark属于重要的大数据计算框架,另外spark还提供了Python的原生API和机器学习组件Spark Ml,使的可以通过Python编写机器学习任务由Spark运行。本篇文件从Spark运行模式开始讲起,重点介绍Spark on Yarn运行模式,最后重点介绍Python on Yarn(即Pyspark on Yarn)上运行原理和案例。
第一部分 Apache Spark运行模式
目前 Apache Spark已知支持5种运行模式。按照节点资源数量可以分为单节点模式(2种)和集群模式(3种)。
- 单节点模式:本地模式、本地伪集群模式
- 集群模式:Standalone模式、Spark on Yarn模式、Spark on Mesos模式
- 原生云模式:在Kubernetes上运行。随着Docker容器和原生云技术的兴起,Spark开始支持在Kubernetes上运行。
对于Spark on Kubernetes可以参考官方文档:https://spark.apache.org/docs/latest/running-on-kubernetes.html。另外可以参考我的另外一篇技术总结:《在Minikube上运行Spark集群》。
1.1 本地模式(单节点模式)
本地模式又称为Loacl[N]模式。该模式只需要在单节点上解压spark包即可运行,使用多个线程模拟Spark分布式计算,Master和Worker运行在同一个JVM虚拟机中。这里参数N代表可以使用(预申请)N个线程资源,每个线程拥有一个Core(默认值N=1)。
如果参数为:Loacl[*],表明:Run Spark locally with as many worker threads as logical cores on your machine。即线程数和物理核数相同。
例如下面的启动命令:
1 | ./spark-submit –class org.apache.spark.examples.JavaWordCount –master local[*] spark-examples_2.11-2.3.1.jar file:///opt/README.md |
该模式不依懒于HDFS分布式文件系统。例如上面的命令使用的本地文件系统。
1.2 本地伪集群模式(单节点模式)
该模式和Local[N]类似,不同的是,它会在单机启动多个进程来模拟集群下的分布式场景,而不像Local[N]这种多个线程在一个进程下共享资源。通常用来测试和验证应用程序逻辑上有没有问题,或者想使用Spark的计算框架而而受限于没有太多资源。
作业提交命令中使用local-cluster[x,y,z]参数模式:x代表要生成的executor数,y和z分别代表每个executor所拥有的core和memory数值。例如下面的命令作业申请了2个executor 进程,每个进程分配3个core和1G的内存,来运行应用程序。
1 | ./spark-submit –master local-cluster[2, 3, 1024] |
1.3 Standalone模式(集群模式)
1.3.1 构架部署
Standalone为spark自带资源管理系统(即经典的Master/Slaves架构模式)。该模式下集群由Master和Worker节点组成,程序通过与Master节点交互申请资源,Worker节点启动Executor运行。具体数据流图如下:

另外考虑到Master节点存在单点故障。Spark支持使用Zookeeper实现HA高可用(high avalible)。Zookeeper提供一种领导选举的机制,通过该机制可以保证集群中只有一个Master节点处于RecoveryState.Active状态,其他Master节点处于RecoveryState.Standby状态。

1.3.2 作业运行模式
在该模式下,用户提交任务有两种方式:Standalone-client和Standalone-cluster。
1.5.1 Client模式
执行流程:
(1)客户端启动Driver进程。
(2)Driver向Master申请启动Application启动需要的资源。
(3)资源申请成功后,Driver将task发送到相应的Worker节点执行,并负责监控task运行情况。
(4)Worker将task执行结果返回到客户端的Driver进程。
Client模式适用于调试程序。Driver进程在客户端侧启动,如果生产采用这种模式,当业务量较大时,客户端需要启动大量Driver进程,会消耗大量系统资源,导致资源枯竭。
1.5.2 Cluster模式
执行流程:
(1)客户端会想Master节点申请启动Driver。
(2)Master受理客户端的请求,分配一个Work节点,启动Driver进程。
(3)Driver启动后,重新想Master节点申请运行资源,Master分配资源,并在相应的Worker节点上启动Executor进程。
(4)Driver发送task到相应的Worker节点运行,并负责监控task。
(5)Worker将task执行结果返回到Driver进程。
Driver运行有Master在集群Worker节点上随机分配,相当于在集群上负载资源。
两种方式最大的区别就是Driver进程运行的位置。Cluster模式相对于Client模式更适合于生成环境的部署。
1.4 Spark on Yarn(集群模式)
目前大部分企业级Spark都是跑在已有的Hadoop集群(hadoop 2.0系统)中,均使用Yarn来作为Spark的Cluster Manager,为Spark提供资源管理服务,Spark自身完成任务调度和计算。这部分内容会在后文中细致介绍。
1.5 Spark on Mesos(集群模式)
参考官方文档介绍:https://spark.apache.org/docs/latest/running-on-mesos.html
第二部分 Spark on Yarn
我们知道MapReduce任务是运行在Yarn上的,同样Spark Application也可以运行在Yarn上。这种模式下,资源的管理、协调、执行和监控交给Yarn集群完成。
Yarn集群上可以运行:MapReduce任务、Spark Application、Hbase集群、Storm集群、Flink集群等等,还有我们后续重点介绍的Python on Yarn。
从节点功能上看,Yarn也采用类似Standalone模式的Master/Slave结构。资源框架中RM(ResourceManager)对应Master,NM(NodeManager)对应Slave。RM负责各个NM资源的统一管理和调度,NM节点负责启动和执行任务以及各任务间的资源隔离。
当集群中存在多种计算框架时,架构上选用Yarn统一管理资源要比Standalone更合适。类似Standalone模式,Spark on Yarn也有两种运行方式:Yarn-Client模式和Yarn-Cluster模式。从适用场景上看,Yarn-Cluster模式适用于生产环境,而Yarn-Client模式更适用于开发(交互式调试)。
2.1 Client模式
在Yarn-client模式下,Driver运行在本地Client上,通过AM(ApplicationMaster)向RM申请资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉Client,相当于kill掉这个spark应用。

- Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend。
- ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派。
- Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container)。
- 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task。
- client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
2.2 Cluster模式
在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
- 第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中先启动。
- 第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成。
应用的运行结果不能在客户端显示(可以在history server中查看),所以最好将结果保存在HDFS而非stdout输出,客户端的终端显示的是作为YARN的job的简单运行状况,下图是yarn-cluster模式:

执行过程:
- Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等。
- ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化。
- ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束。
- 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,而Executor对象的创建及维护是由。CoarseGrainedExecutorBackend负责的,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等。
- ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
2.3 两种模式的比较
在client模式下,Spark Application运行的Driver会在提交程序的节点上,而该节点可以是YARN集群内部节点,也可以不是。一般来说提交Spark Application的客户端节点不是YARN集群内部的节点,那么在客户端节点上可以根据自己的需要安装各种需要的软件和环境,以支撑Spark Application正常运行。在cluster模式下,Spark Application运行时的所有进程都在YARN集群的NodeManager节点上,而且具体在哪些NodeManager上运行是由YARN的调度策略所决定的。
对比这两种模式,最关键的是Spark Application运行时Driver所在的节点不同,而且,如果想要对Driver所在节点的运行环境进行配置,区别很大,但这对于PySpark Application运行来说是非常关键的。
第三部分 Pyspark Application原理
PySpark是Spark为使用Python程序编写Spark Application而实现的客户端库,通过PySpark也可以编写Spark Application并在Spark集群上运行。Python具有非常丰富的科学计算、机器学习处理库,如numpy、pandas、scipy等等。为了能够充分利用这些高效的Python模块,很多机器学习程序都会使用Python实现,同时也希望能够在Spark集群上运行。
理解PySpark Application的运行原理,有助于我们使用Python编写Spark Application,并能够对PySpark Application进行各种调优。PySpark构建于Spark的Java API之上,数据在Python脚本里面进行处理,而在JVM中缓存和Shuffle数据,数据处理流程如下图所示:
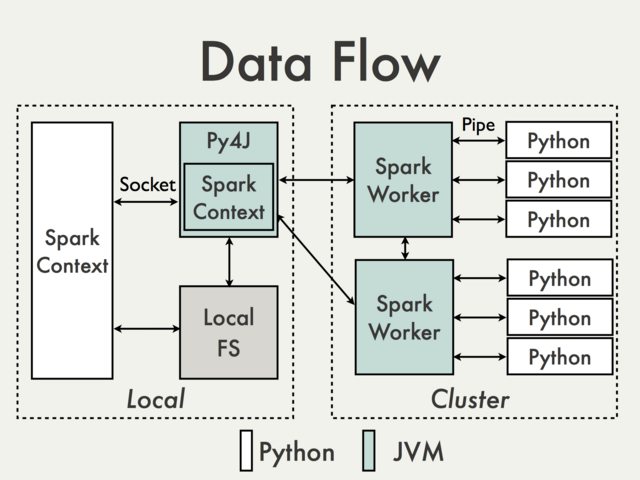
Spark Application会在Driver中创建pyspark.SparkContext对象,后续通过pyspark.SparkContext对象来构建Job DAG并提交DAG运行。使用Python编写PySpark Application,在Python编写的Driver中也有一个pyspark.SparkContext对象,该pyspark.SparkContext对象会通过Py4J模块启动一个JVM实例,创建一个JavaSparkContext对象。PY4J只用在Driver上,后续在Python程序与JavaSparkContext对象之间的通信,都会通过PY4J模块来实现,而且都是本地通信。
PySpark Application中也有RDD,对Python RDD的Transformation操作,都会被映射到Java中的PythonRDD对象上。对于远程节点上的Python RDD操作,Java PythonRDD对象会创建一个Python子进程,并基于Pipe的方式与该Python子进程通信,将用户编写Python处理代码和数据发送到Python子进程中进行处理。
第四部分 Python on Yarn配置及运行
4.1 Yarn节点配置Python环境
该模式需要在Yarn集群上每个NM节点(Node Manager)上部署Python编译环境,即安装Python安装包、依赖模块。用户编写的Pyspark Application由集群中Yarn调度执行。
通常使用Anaconda安装包进行统一部署,简化环境的部署。
该模式存在下面缺点:
- 新增依赖包部署安装代价大。如果后续用户编写的Spark Application需要依赖新的Python模块或包,那么就需要依次在集群Node Manager上部署更新依赖包。
- 用户对于Python环境的依赖差异化无法满足。通常不同用户编写Spark Application会依赖不同的Python环境,比如Python2、Python3环境等等。该模式下只能支持一种环境,无法满足Python多环境的需求。
- 各节点的Python环境需要统一。由于用户提交的Spark Application具体在哪些Node Manager上执行,由YARN调度决定,所以必须保证每个节点的Python环境(基础环境+依赖环境)都是相同的,环境维护成本高。
4.2 Yarn节点不配置Python环境
该模式不需要提前在集群Node Manager上预安装Python环境。
我们基于华为C60集群(开源集群相同)以及Anaconda环境对该模式进行了测试验证。具体实现思路如下所示:
- 在一台SUSE节点上部署Anaconda,并创建虚拟Python环境(如果需要可以部署安装部分依赖包)。
- 创建conda虚拟环境,并整体打包为zip文件。
- 用户提交PySpark Application时,使用
--archives参数指定该zip文件路径。
详细操作步骤如下:
- 第一步
下载Anaconda3-4.2.0-Linux-x86_64.sh安装软件(基于python3.5),在SUSE服务器上部署安装。Anaconda的安装路径为/usr/anaconda3。查看客户端服务器的python环境清单:
1 | dkfzxwma07app08:/usr/anaconda3 # conda env list |
其中root环境为目前的主环境。为了便于环境版本管理我们新建一个专用环境(mlpy_env)。
1 | dkfzxwma07app08:/usr/anaconda3/envs # conda create -n mlpy --clone root |
上述命令创建了一个名称为mlpy_env的Python环境,clone选项将对应的软件包都安装到该环境中,包括一些C的动态链接库文件。
接着,将该Python环境打包,执行如下命令:
1 | dkfzxwma07app08:/usr/anaconda3/envs # cd /root/anaconda2/envs |
将该zip压缩包拷贝到指定目录中(或者后续引用使用绝对路径),方便后续提交PySpark Application:
1 | dkfzxwma07app08:/usr/anaconda3/envs # cp mlpy_env.zip /tmp/ |
最后,我们可以提交我们的PySpark Application,执行如下命令(或打包成shell脚本):
1 | PYSPARK_PYTHON=./ANACONDA/mlpy_env/bin/python |
注意:下面命令指的是zip包将在ANACONDA的目录中展开,需要注意路径。
2
环境打包需要注意压缩路径。
上面的依赖zip压缩包将整个Python的运行环境都包含在里面,在提交PySpark Application时会将该环境zip包上传到运行Application的所在的每个节点上。解压缩后为Python代码提供运行时环境。如果不想每次都从客户端将该环境文件上传到集群中运行节点上,也可以提前将zip包上传到HDFS文件系统中,并修改–archives参数的值为hdfs:///tmp/mlpy_env.zip #ANACONDA(注意环境差异),也是可以的。
另外,需要说明的是,如果我们开发的/var/lib/hadoop-hdfs/pyspark /test_pyspark_dependencies.py文件中,依赖多个其他Python文件,想要通过上面的方式运行,必须将这些依赖的Python文件拷贝到我们创建的环境中,对应的目录为mlpy_env/lib/python2.7/site-packages/下面。
注意:pyspark不支持python3.6版本,所以python环境使用python3.5
否则程序执行回显会有这样的报错信息:
TypeError: namedtuple() missing 3 required keyword-only arguments: ‘verbose’, ‘rename’, and ‘module’
4.3 一个机器学习任务栗子
举一个Kmeans无监督算法的Python案例:
1 | import os |
整理成下面的提交命令,将作业提交到Yarn集群:
1 | dkfzxwma07app08:/tmp/pyspark # cat run.sh |
模型训练结果会写到路径下面:/user/model:
1 | dkfzxwma07app08:/tmp/pyspark/pythonpkg # hdfs dfs -ls /user/model |
模型加载的预测结果可以在Yarn日志中查询:
1 | dkfzxwma07app08:/tmp/pyspark # yarn logs -applicationId application_1562162322775_150207 |
当然对于输出可以选择其他输出源(表或者文件)。
第五部分 总结
5.1 混合多语言数据流
通常一个完整的机器学习应用的数据流设计中,可以将数据ETL准备阶段和算法计算分离出来。使用Java/scala/sql进行数据的预处理,输出算法计算要求的数据格式。这会极大降低算法计算的数据输入规模,降低算法计算的节点的IO。
机器学习的算法计算部分具有高迭代计算特性,对于非分布式的机器学习算法,我们通常部署在高性能的节点上,基于丰富、高性能的Python科学计算模块,使用Python语言实现。而对于数据准备阶段,更适合使用原生的Scala/java编程语言实现Spark Application来处理数据,包括转换、统计、压缩等等,将满足算法输入格式的数据输出到HDFS文件系统中。特别对于数据规模较大的情况,在Spark集群上处理数据,Scala/Java实现的Spark Application运行(多机并行分布式处理)性能要好一些。然后输出数据交给Python进行迭代计算训练。
当然对于分布式机器学习框架,将数据迭代部分分解到多个节点并行处理,由参数服务器管理迭代参数的汇总和更新。在这种计算框架下可以利用数据集群天然的计算资源,实现分布式部署。这就形成了一个高效的混合的多语言的数据处理流。
5.2 架构建议和总结
1、对于Python on Yarn架构下,采用“Yarn节点不配置Python环境”模式,便于Python环境的管理。这时候可以将Python环境zip文件上传至集群HDFS文件系统,避免每次提交任务都需要上传zip文件,但是不可避免集群内部HDFS文件系统分发到运行节点产生的网络IO。但比集群外部的上传效率高。
2、对于机器学习任务数据流建议采用混合多语言数据流方式,发挥各计算组件的优势。
3、对于分布式机器学习框架,建议结合集群的计算资源,直接在集群上展开分布式计算(例如Tensorflow计算框架)。而不是单独新建新的机器学习分布式集群。减少两个集群的数据搬运,并且使得数据和计算更加贴近,最重要的提高机器学习任务端到端的效率。
参考文献及资料
1、Running Spark Python Applications,链接:https://www.cloudera.com/documentation/enterprise/5-9-x/topics/spark_python.html
2、基于YARN集群构建运行PySpark Application,链接: http://shiyanjun.cn/archives/1738.html
3、Running Spark on YARN,链接: https://spark.apache.org/docs/latest/running-on-yarn.html
4、Running Spark on Kubernetes,链接:https://spark.apache.org/docs/latest/running-on-kubernetes.html
5、Apache Spark Resource Management and YARN App Models,链接:https://blog.cloudera.com/blog/2014/05/apache-spark-resource-management-and-yarn-app-models/
6、Spark On Yarn的两种模式yarn-cluster和yarn-client深度剖析,链接:https://www.cnblogs.com/ITtangtang/p/7967386.html
7、Introducing Skein: Deploy Python on Apache YARN the Easy Way,链接:https://jcrist.github.io/introducing-skein.html
8、当Spark遇上TensorFlow分布式深度学习框架原理和实践,链接:https://juejin.im/post/5ad4b620f265da23a04a0ad0
9、Spark On Yarn的优势,链接:https://www.cnblogs.com/ITtangtang/p/7967386.html
10、基于YARN集群构建运行PySpark Application,链接:http://www.uml.org.cn/bigdata/201711132.asp