
[TOC]
背景
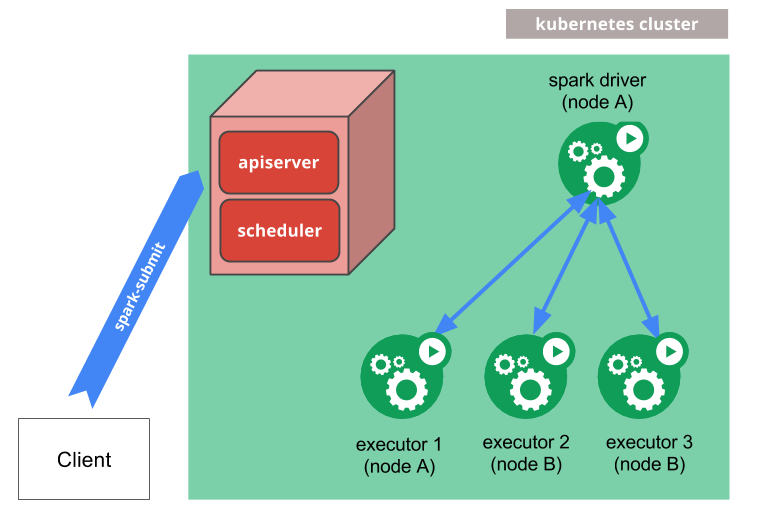
Spark2.3版本开始支持使用spark-submit直接提交任务给Kubernetes集群。执行机制原理:
- Spark创建一个在Kubernetes pod中运行的Spark驱动程序。
- 驱动程序创建执行程序,这些执行程序也在Kubernetes pod中运行并连接到它们,并执行应用程序代码。
- 当应用程序完成时,执行程序窗格会终止并清理,但驱动程序窗格会保留日志并在Kubernetes API中保持“已完成”状态,直到它最终被垃圾收集或手动清理。
第一部分 环境准备
1.1 minikube虚拟机准备
由于spark集群对内存和cpu资源要求较高,在minikube启动前,提前配置较多的资源给虚拟机。
当minikube启动时,它以单节点配置开始,默认情况下占用
1Gb内存和2CPU内核,但是,为了运行spark集群,这个资源配置是不够的,而且作业会失败。
1 | minikube config set memory 8192 |
或者用下面的命令启集群
1 | minikube start --cpus 2 --memory 8192 |
1.2 Spark环境准备
第一步 下载saprk2.3
1 | wget http://apache.mirrors.hoobly.com/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz |
解压缩:
1 | tar xvf spark-2.3.0-bin-hadoop2.7.tgz |
制作docker镜像
1 | cd spark-2.3.0-bin-hadoop2.7 |
查看镜像情况:
1 | docker images |
登录docker 账户:
1 | docker login |
将之前build好的镜像pull到docker hub上:
1 | docker push rongxiang1986/spark:2.3.0 |
注意这里的格式要求(我踩坑了):docker push 注册用户名/镜像名
在https://hub.docker.com/上查看,镜像确实push上去了。
第二部分 提交Spark作业
2.1 作业提交
提前配置serviceaccount信息。
1 | kubectl create serviceaccount spark |
提交作业:
1 | ./spark-submit \ |
提交命令的参数含义分别是:
--class:应用程序的入口点(命令中使用:org.apache.spark.examples.SparkPi);--master:Kubernetes集群的URL(k8s://https://192.168.99.100:8443);--deploy-mode:驱动程序部署位置(默认值:客户端),这里部署在集群中;--conf spark.executor.instances=2:运行作业启动的executor个数;--conf spark.kubernetes.container.image=rongxiang1986/spark:2.3.0:使用的docker镜像名称;local:///opt/spark/examples/jars/spark-examples_2.11-2.3.0.jar:应用程序依赖jar包路径;
注意:目前deploy-mode只支持cluster模式,不支持client模式。
Error: Client mode is currently not supported for Kubernetes.
作业运行回显如下:
1 | 2018-08-12 15:51:17 WARN Utils:66 - Your hostname, deeplearning resolves to a loopback address: 127.0.1.1; using 192.168.31.3 instead (on interface enp0s31f6) |
2.2 日志查询
可以通过命令查看容器执行日志,或者通过kubernetes-dashboard提供web界面查看。
1 | kubectl logs spark-pi-709e1c1b19813e7cbc1aeff45200c64e-driver |
1 | 2018-08-12 07:51:57 INFO DAGScheduler:54 - Job 0 finished: reduce at SparkPi.scala:38, took 0.576528 s |
执行结束后executor pod被自动清除。计算得到pi的值为:
1 | Pi is roughly 3.1336756683783418 |
如果作业通过cluster提交,driver容器会被保留,可以查看:
1 | minikube service list |
第三部分 常见报错异常处理
1、如果遇到下面的报错信息,可能是Spark版本太低,建议升级大于2.4.5+以上版本后重试。
1 | 2020-08-09 10:13:14 WARN KubernetesClusterManager:66 - The executor's init-container config map is not specified. Executors will therefore not attempt to fetch remote or submitted dependencies. |
2、如果发现拉取镜像的比较慢,或者任务状态一直停留也pulling。这是由于minikube主机中本地是没有这个私有镜像,需要进入minikube组件提前将dockerhub中的远程镜像拉取到本地。否则每次提交任务,都会从远程拉取,由于网络条件的限制(你懂的),导致每次拉取都很慢或者超时。
1 | root@deeplearning:~# minikube ssh |
2、spark 任务每个容器至少需要一个CPU,如果启动的minikube集群的资源是默认的2CPU,如果单个任务申请多个执行器就会报资源不足。所以在创建minikube集群时,提前分配足够的资源。
参考文献
1、Running Spark on Kubernetes :https://spark.apache.org/docs/latest/running-on-kubernetes.html
2、在Minikube Kubernetes集群上运行Spark工作:https://iamninad.com/running-spark-job-on-kubernetes-minikube/