
目录
背景
第一部分
alias配置和取消第二部分
alias查看参考文献及资料
背景
MLlib 是 Spark 的机器学习库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。
MLlib 由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道 API。
本节将对 Spark MLlib 进行简单介绍,在介绍数据挖掘算法时,将使用 Spark MLlib 提供的算法进行实例讲解。
Spark MLlib的构成
Spark 是基于内存计算的,天然适应于数据挖掘的迭代式计算,但是对于普通开发者来说,实现分布式的数据挖掘算法仍然具有极大的挑战性。因此,Spark 提供了一个基于海量数据的机器学习库 MLlib,它提供了常用数据挖掘算法的分布式实现功能。
开发者只需要有 Spark 基础并且了解数据挖掘算法的原理,以及算法参数的含义,就可以通过调用相应的算法的 API 来实现基于海量数据的挖掘过程。
MLlib 由 4 部分组成:数据类型,数学统计计算库,算法评测和机器学习算法。
| 名称 | 说明 |
|---|---|
| 数据类型 | 向量、带类别的向量、矩阵等 |
| 数学统计计算库 | 基本统计量、相关分析、随机数产生器、假设检验等 |
| 算法评测 | AUC、准确率、召回率、F-Measure 等 |
| 机器学习算法 | 分类算法、回归算法、聚类算法、协同过滤等 |
具体来讲,分类算法和回归算法包括逻辑回归、SVM、朴素贝叶斯、决策树和随机森林等算法。用于聚类算法包括 k-means 和 LDA 算法。协同过滤算法包括交替最小二乘法(ALS)算法。
Spark 机器学习库从 1.2 版本以后被分为两个包:
spark.mllib包含基于RDD的原始算法API。Spark MLlib 历史比较长,在1.0 以前的版本即已经包含了,提供的算法实现都是基于原始的 RDD。spark.ml则提供了基于DataFrames 高层次的API,可以用来构建机器学习工作流(PipeLine)。ML Pipeline 弥补了原始 MLlib 库的不足,向用户提供了一个基于 DataFrame 的机器学习工作流式 API 套件。
使用 ML Pipeline API可以很方便的把数据处理,特征转换,正则化,以及多个机器学习算法联合起来,构建一个单一完整的机器学习流水线。这种方式给我们提供了更灵活的方法,更符合机器学习过程的特点,也更容易从其他语言迁移。Spark官方推荐使用spark.ml。如果新的算法能够适用于机器学习管道的概念,就应该将其放到spark.ml包中,如:特征提取器和转换器。开发者需要注意的是,从Spark2.0开始,基于RDD的API进入维护模式(即不增加任何新的特性),并预期于3.0版本的时候被移除出MLLib。
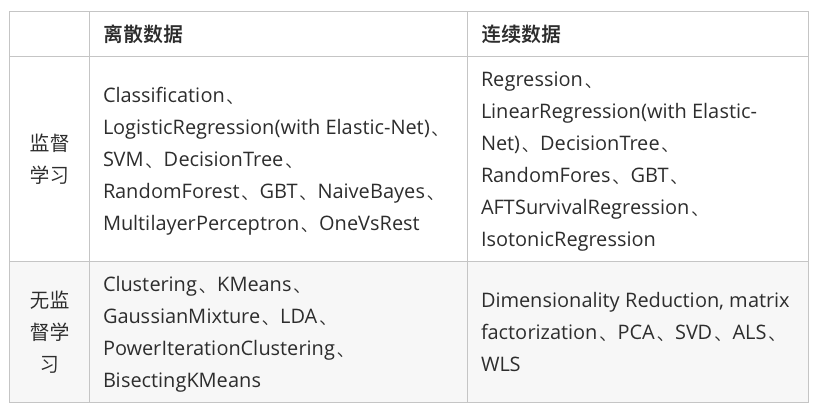
Spark在机器学习方面的发展非常快,目前已经支持了主流的统计和机器学习算法。纵观所有基于分布式架构的开源机器学习库,MLlib可以算是计算效率最高的。MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤。下表列出了目前MLlib支持的主要的机器学习算法:
Spark MLlib 的优势
相比于基于 Hadoop MapReduce 实现的机器学习算法(如 Hadoop Manhout),Spark MLlib 在机器学习方面具有一些得天独厚的优势。
首先,机器学习算法一般都有由多个步骤组成迭代计算的过程,机器学习的计算需要在多次迭代后获得足够小的误差或者足够收敛时才会停止。如果迭代时使用 Hadoop MapReduce 计算框架,则每次计算都要读/写磁盘及完成任务的启动等工作,从而会导致非常大的 I/O 和 CPU 消耗。
而 Spark 基于内存的计算模型就是针对迭代计算而设计的,多个迭代直接在内存中完成,只有在必要时才会操作磁盘和网络,所以说,Spark MLlib 正是机器学习的理想的平台。其次,Spark 具有出色而高效的 Akka 和 Netty 通信系统,通信效率高于 Hadoop MapReduce 计算框架的通信机制。
在 Spark 官方首页中展示了 Logistic Regression 算法在 Spark 和 Hadoop 中运行的性能比较,可以看出 Spark 比 Hadoop 要快 100 倍以上。
MLlib(Machine Learnig lib) 是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。Spark的设计初衷就是为了支持一些迭代的Job, 这正好符合很多机器学习算法的特点。在Spark官方首页中展示了Logistic Regression算法在Spark和Hadoop中运行的性能比较,如图下图所示。


第四部分 参数调优
参考文献及资料
1、Reindex from a remote cluster,链接:https://www.elastic.co/guide/en/elasticsearch/reference/current/reindex-upgrade-remote.html