
目录
- 背景
- 第一部分 Spark内存管理详解
- 第二部分 Spark参数说明
- 第三部分 Spark内存优化
- 第四部分 常见线上问题解决
- 参考文献及资料
背景
数据湖技术实现上,有开源三剑客(Hudi,Delta Lake,Iceberg),本篇文章主要介绍其中一员:Iceberg。Iceberg官网产品介绍:
Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark, Trino, Flink, Presto, and Hive to safely work with the same tables, at the same time.
Iceberg是一个用于海量数据分析表的高性能格式。也就是说Iceberg本质是一种表格格式。表是一个具象的概念,应用层面的概念,我们天天说的表是简单的行和列的组合。而表格式是数据库系统实现层面一个抽象的概念,它定义了一个表中包含哪些字段,表下面文件的组织形式、表索引信息、统计信息以及上层查询引擎读取、写入表中文件的接口。
我们可以简单理解为他是基于计算层(flink、spark)和存储层(orc、parqurt)的一个中间层,我们可以把它定义成一种“数据组织格式”,Iceberg将其称之为“表格式”也是表达类似的含义。他与底层的存储格式(比如ORC、Parquet之类的列式存储格式)最大的区别是,它并不定义数据存储方式,而是定义了数据、元数据的组织方式,向上提供统一的“表”的语义。它构建在数据存储格式之上,其底层的数据存储仍然使用Parquet、ORC等进行存储。在hive建立一个iceberg格式的表。用flink或者spark写入iceberg,然后再通过其他方式来读取这个表,比如spark、flink、presto等。
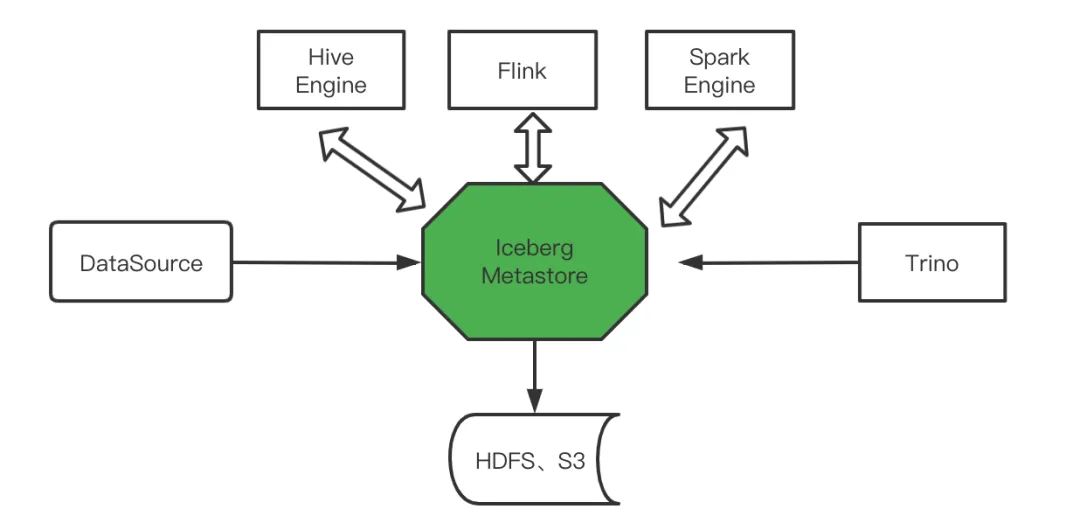
Iceberg的架构和实现并未绑定于某一特定引擎,它实现了通用的数据组织格式,利用此格式可以方便地与不同引擎(如Flink、Hive、Spark)对接。
https://www.cnblogs.com/swordfall/p/14548574.html
https://iceberg.apache.org/docs/latest/flink/
第一部分 预备知识:表格格式
传统的大数据仓库我们通常是基于Hadoop生态中Hive进行建设,技术上Hive底层的存储是基于HDFS分布式文件系统。HDFS的文件存储有多种方式:Text、Json、Parquet、ORC等。而对于实时查询要求较高的场景我们将数据存储在HBase中,而HBase的文件个是HFile。
第二部分 Iceberg的表格格式
2. Iceberg优势
- 增量读取处理能力:Iceberg支持通过流式方式读取增量数据,支持Structed Streaming以及Flink table Source;
- 支持事务(ACID),上游数据写入即可见,不影响当前数据处理任务,简化ETL;提供upsert和merge into能力,可以极大地缩小数据入库延迟;
- 可扩展的元数据,快照隔离以及对于文件列表的所有修改都是原子操作;
- 同时支持流批处理、支持多种存储格式和灵活的文件组织:提供了基于流式的增量计算模型和基于批处理的全量表计算模型。批处理和流任务可以使用相同的存储模型,数据不再孤立;Iceberg支持隐藏分区和分区进化,方便业务进行数据分区策略更新。支持Parquet、Avro以及ORC等存储格式。
- 支持多种计算引擎,优秀的内核抽象使之不绑定特定的计算引擎,目前Iceberg支持的计算引擎有Spark、Flink、Presto以及Hive。
第三部分 创建Iceberg表
Apache Iceberg支持多种方式创建Iceberg表,其中包括使用catalog方式(所谓Catalog就是一系列创建、删除、加载表的操作API(A Catalog API for table create, drop, and load operations))或实现org.apache.iceberg.Tables接口。
Apache Iceberg支持Apache Flink的DataStream Api和Table Api写记录进iceberg表。当前,我们只集成Iceberg和apache flink 1.11.x。
当然,Apache Iceberg 表元数据存储地方是可插拔的,所以我们完全可以自定义元数据存储的方式
3.0 计算引擎
3.0.1 Flink
需要下载两个依赖包:
1 | https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-flink-runtime/0.12.1/iceberg-flink-runtime-0.12.1.jar |
启动flink sql client,可以创建hadoop catalog如下:
1 | ./bin/sql-client.sh embedded -j lib/flink-runtime_2.12-1.12.7.jar shell |
启动flink sql client,带hive connector jar包,可以创建hadoop catalog和hive catalog如下:
1 | ./bin/sql-client.sh embedded \ |
3.0.2 Spark
https://jishuin.proginn.com/p/763bfbd55830
3.0.3 Hive
https://www.cxybb.com/article/qq_31866793/116169683
3.1 catalog
Flink1.11支持通过flink sql创建catalogs。catalog是Iceberg对表进行管理(create、drop、rename等)的一个组件。目前Iceberg主要支持HiveCatalog和HadoopCatalog两种Catalog。其中HiveCatalog将当前表metadata文件路径存储在hive Metastore,这个表metadata文件是所有读写Iceberg表的入口,所以每次读写Iceberg表都需要先从hive Metastore中取出对应的表metadata文件路径,然后再解析这个Metadata文件进行接下来的操作。而HadoopCatalog将当前表metadata文件路径记录在一个文件目录下,因此不需要连接hive Metastore。
Catalog元数据本身既可以存储到Hadoop HDFS文件系统也可以存储在Hive Metastore(HMS)。
3.1.1 Hive catalog
Hive catalog 是通过连接 Hive 的 MetaStore,把 Iceberg 的表存储到其中,它的实现类为 org.apache.iceberg.hive.HiveCatalog
创建一个名为hive_catalog的 iceberg catalog ,用来从 hive metastore 中加载表。
1 | CREATE CATALOG hive_catalog WITH ( |
参数说明:
- type: 只能使用iceberg,用于 iceberg 表格式。(必须)
- catalog-type: Iceberg 当前支持hive或hadoopcatalog 类型。(必须)
- uri: Hive metastore 的 thrift URI。 (必须)
- clients: Hive metastore 客户端池大小,默认值为 2。 (可选)
- property-version: 版本号来描述属性版本。此属性可用于在属性格式发生更改时进行向后兼容。当前的属性版本是 1。(可选)
- warehouse: Hive 仓库位置, 如果既不将 hive-conf-dir 设置为指定包含 hive-site.xml 配置文件的位置,也不将正确的 hive-site.xml 添加到类路径,则用户应指定此路径。
- hive-conf-dir: 包含 Hive-site.xml 配置文件的目录的路径,该配置文件将用于提供自定义的 Hive 配置值。 如果在创建 iceberg catalog 时同时设置 hive-conf-dir 和 warehouse,那么将使用 warehouse 值覆盖 < hive-conf-dir >/hive-site.xml (或者 classpath 中的 hive 配置文件)中的 hive.metastore.warehouse.dir 的值。
3.1.2 Hadoop catalog
Iceberg 还支持 HDFS 中基于目录的 catalog ,可以使用’catalog-type’=’hadoop’进行配置:
1 | CREATE CATALOG hadoop_catalog WITH ( |
- warehouse:hdfs目录存储元数据文件和数据文件。(必须)
我们可以执行sql命令USE CATALOG hive_catalog来设置当前的catalog。
3.1.3 Hadoop catalog
Flink也支持通过指定catalog-impl属性来加载自定义的Iceberg catalog接口。当catalog-impl设置了,catalog-type的值可以忽略,这里有个例子:
1 | CREATE CATALOG my_catalog WITH ( |
3.1.4 Hadoop catalog
在启动SQL客户端之前,Catalogs可以通过在sql-client-defaults.yaml文件中注册。这里有个例子:
1 | catalogs: |
3.2 文件表的组织形式
1. HiveCatalog
1 | hadoop@xxx:~$ hdfs dfs -ls /libis/hive-2.3.6/hive_iceberg.db/action_logs |
其中data目录下存储数据文件,metadata目录下存储元数据文件。
2. metadata目录
 ;)
;)
1 | hadoop@xxx:~$ hdfs dfs -ls /libis/hive-2.3.6/hive_iceberg.db/action_logs/metadata |
;)
其中00001-62ade8ab-c1cf-40d3-bc21-fd5027bc3a55.metadata.json中存储表的shcema、partition spec以及当前snapshot manifests文件路径。snap-6771375506965563160-1-bb641961-162a-49a8-b567-885430d4e799.avro存储manifest文件路径。bb641961-162a-49a8-b567-885430d4e799-m0.avro记录本次提交的文件以及文件级别元数据。
3. data目录
1 | hadoop@xxx:~$ hdfs dfs -ls /libis/hive-2.3.6/hive_iceberg.db/action_logs/data/event_time_hour=2020-06-04-19/action=click |
4. HadoopCatalog
Hadoopcatalog与Hivecatalog的data目录完全相同,metadata目录下文件稍有不同,HadoopCatalog管理的metadata目录如下所示:
;)
1 | hadoop@xxx:~$ hdfs dfs -ls /libis/hive-2.3.6/hadoop_iceberg/action_logs/metadata |
;)
说明该表的最新snapshot_id是2,即对应的snapshot元数据文件是v2.metadata.json,解析v2.metadata.json可以获取到该表当前最新snapshot对应的scheme、partition spec、父snapshot以及该snapshot对应的manifestList文件路径等,因此version-hint.text是HadoopCatalog获取当前snapshot版本的入口。
HiveCatalog的metadata目录下并没有version-hint.text文件,那它获取当前snapshot版本的入口在哪里呢?它的入口在Metastore中的schema里面,可以在HiveCatalog建表schema中的TBPROPERTIES中有个key是“metadata_location”,对应的value就是当前最新的snapshot文件。因此,有两点需要说明:
- HiveCatalog创建的表,每次提交写入文件生成新的snapshot后都需要更新Metastore中的metadata_location字段。
- HiveCatalog和HadoopCatalog不能混用。即使用HiveCatalog创建的表,再使用HadoopCatalog是不能正常加载的,反之亦然。
3.3 技术选择
上面说到Iceberg目前支持两种Catalog,而且两种Catalog相互不兼容。那这里有两个问题:
- 社区是出于什么考虑实现两种不兼容的Catalog?
- 因为两者不兼容,必须选择其一作为系统唯一的Catalog,那是选择HiveCatalog还是HadoopCatalog,为什么?
先回答第一个问题。社区是出于什么考虑实现两种不兼容的Catalog?
在回答这个问题之前,首先回顾一下上一篇文章中介绍到的基于HadoopCatalog,Iceberg实现数据写入提交的ACID机制,最终的结论是使用了乐观锁机制和HDFS rename的原子性一起保障写入提交的ACID。如果某些文件系统比如S3不支持rename的原子性呢?那就需要另外一种机制保障写入提交的ACID,HiveCatalog就是另一种不依赖文件系统支持,但是可以提供ACID支持的方案,它在每次提交的时候都更新MySQL中同一行记录,这样的更新MySQL本身是可以保证ACID的。这就是社区为什么会支持两种不兼容Catalog的本质原因。
再来回答第二个问题。HadoopCatalog依赖于HDFS提供的rename原子性语义,而HiveCatalog不依赖于任何文件系统的rename原子性语义支持,因此基于HiveCatalog的表不仅可以支持HDFS,而且可以支持s3、oss等其他文件系统。但是HadoopCatalog可以认为只支持HDFS表,比较难以迁移到其他文件系统。但是HadoopCatalog写入提交的过程只依赖HDFS,不和Metastore/MySQL交互,而HiveCatalog每次提交都需要和Metastore/MySQL交互,可以认为是强依赖于Metastore,如果Metastore有异常,基于HiveCatalog的Iceberg表的写入和查询会有问题。相反,HadoopCatalog并不依赖于Metastore,即使Metastore有异常,也不影响Iceberg表的写入和查询。
考虑到我们目前主要还是依赖HDFS,同时不想强依赖于Metastore,所以我们选择HadoopCatalog作为我们系统唯一的Catalog。即使有一天,想要把HDFS上的表迁移到S3上去,也是可以办到的,大家想想,无论是HadoopCatalog还是HiveCatalog,数据文件和元数据文件本身都是相同的,只是标记当前最新的snapshot的入口不一样,那只需要简单的手动变换一下入口就可以实现Catalog的切换,切换到HiveCatalog上之后,就可以摆脱HDFS的依赖,问题并不大。
第四部分 Benchmark测试
4.1 测试集介绍
Star Schema Benchmark(SSB)Star-Schema-Benchmark 测试是一个轻量级的数仓场景下的性能测试集。SSB基于 TPC-HStar-Schema-Benchmark 测试。提供了一个简化版的星形模型数据集,主要用于测试在星形模型下,多表关联查询的性能表现。
1 | git clone git@github.com:vadimtk/ssb-dbgen.git |
考虑到测试环境资源,使用-s 10级别。
注:使用-s 100dbgen 将生成 6 亿行数据(67GB), 如果使用-s 1000它会生成 60 亿行数据(这需要很多时间))
1 | ./dbgen -s 10 -T c |
一共生成4张维度表(customer,part,dwdate,supplier)和一张事实表(lineorder)
1 | root@deeplearning:/data/benchmark/ssb-dbgen# ll -h|grep tbl |
4.2 环境准备
参考文献及资料
1、Star Schema Benchmark,链接:https://clickhouse.com/docs/zh/getting-started/example-datasets/star-schema/